

Blockchain Analytics
The aim of this blog is to demonstrate the concept of blockchain and private distributed ledger with respect to privacy-preserving data science. The blog also states the currently used blockchain analytics techniques for blockchain-oriented data science, visualization techniques, and benchmarking of popular blockchain frameworks which highlight some significant limitations in Ethereum, Parity, and Hyperledger blockchain frameworks.
Let me know your thoughts in the comments section below.
Blockchain technology has become popular in the last decade [1]. The blockchain is a public ledger that records a list of transactions in the distributed network. The first introduction of blockchain technology was by Satoshi Nakamoto who introduced Bitcoin cryptocurrency. Since then, the technology has found its place in many different decentralized systems. As technology revolutionized transactions and exchanges, it has been widely used in industrial applications. Some of the popular blockchain frameworks are Bitcoin, Ethereum, IBM Hyperledger, etc.
Blockchains allow parties that do not trust each other to exchange transactions and agree on a common view of their balances. It enables auditability and traceability in order to detect potential malicious operations in a shared state. Blockchains can be operated reliably in a completely decentralized manner without the need to involve a central trusted instance.
This blog assumes that the general underlying mechanism of the blockchain structure is well understood by the reader.
1. BLOCKCHAIN ORIENTED DATA SCIENCE
A blockchain framework is capable of generating huge volumes of data as it is designed to track every single transaction in the distributed network. Although, this develops the need to have some data analytics mechanism in place to keep a track of number of things like money flows, user behaviour, transaction fees, analysis of entity relationships etc. With this, the need for some efficient underlying blockchain database for querying the blockchain data is also developed. There are also some limitations with respect to blockchains which restrict its wide scale use. We will be discussing this in section 3. But for now, let’s assume that everything is good and we have an efficient data model for querying our blockchain system. Let’s keep this in mind while following through this section.
There are many visualization techniques being used and produced in the industrial and academic literature [1]. Before analysing any blockchain system, it is important to understand every element in the blockchain framework. There are three types of blockchain frameworks:
- Public – Anyone can participate and join the consensus.
- Private – Fully controlled by an organization.
- Consortium – These are semi-private blockchains that restrict the consensus process to selected groups.
Each of these frameworks may have most of the components in common. Let’s take an example of the Bitcoin framework and use this as our baseline for understanding how we can perform data analytics on a Bitcoin framework. Before jumping into analytics, let’s understand different components of a Bitcoin framework:
- Transaction:
- It is the most granular level of blockchain data.
- Transaction records the transfer of value between addresses.
- Blocks:
- Transaction records are stored in blocks.
- They hold and group a certain number of transactions.
- Ledger:
- Multiple blocks are connected in a linked list called as Ledger.
- Nodes:
- Electronic devices that maintain and distribute a copy of the ledger in the blockchain network to maintain synchronization of data.
- Miners:
- Special nodes in peer to peer networks that participate in verifying transactions and adding new blocks to the ledger, with the possibility to receive a reward.
- Entity:
- Represents real blockchain user or organization behind a transaction.
By knowing all the components within a blockchain system, we get to understand where to look for a particular type of data for doing analytics.
Tovanich et al. proposed a taxonomy of blockchain analytics for the Bitcoin framework based on analysis themes:
- Analysis of entity relationship
- Metadata
- Money flows
- User behaviour
- Transaction fee
- Market wallets
This taxonomy helps to frame our analytics goals for analyzing any kind of blockchain framework depending on the task domain. For example, for a Bitcoin framework following can be the analysis goals:
- Anonymity
- Market analytics
- Cyber Crime
- Metadata analysis
- Transaction fees
Any data science activity for blockchain framework can be classified into two types:
- Analysis tasks – Based on the analytics goals.
- Visual representations – of blockchain data or system.
Tovanich et al. introduced a classification scheme of visualization on blockchain data:
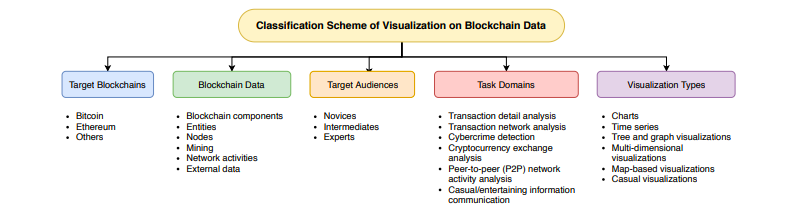
In the proposed classification scheme, we are going to focus in detail on the Task Domains for data analysis which would give a depth on the goals of blockchain analysis tasks based on task domains:
- Transaction detail analysis:
The goal here is to analyze transaction patterns for individual blockchain components or derived entities in blockchain networks.
- Transaction network analysis:
The aim of this type of analysis is to show three kinds of information:
- Transaction networks
- Network entities
- Value flows tracing the transfer of cryptocurrency values through transactions over time.
They are mostly represented by directed bipartite graphs.
- Cyber crime detection:
This includes visualizations that are able to detect suspicious transactions and entities or investigate cyber attack events. A popular technique is a value-flow analysis that allows us to visualize a deep transaction flow graph to trace money laundering and stolen Bitcoins.
- Crypto currency exchange analysis:
This is used to visualize crypto currency conversions from crypto values into real world currencies. Mostly used for visualizing conversion rates for cryptocurrency values and market analysis.
- P2P network activity analysis:
This type of analysis is used to visualize time series to show the aggregated statistics of P2P networks. Map-based visualizations to show the geographical distribution of blockchain usage around the world.
- Casual / Entertainment Purpose:
Such kind of analytics is used for visual encodings and understanding of blockchain networks, maybe for casual entertainment or entertainment purposes. Example of such analytics if Bitcoin VR, it is an open source project that visualizes Bitcoin transactions as balloons flying over a 360 degree view.
2. DATA MODELLING FOR BLOCKCHAIN FRAMEWORK
For performing efficient data analytics on a blockchain framework, it is important to have a managed underlying data model which enables systematic blockchain data analysis. El-Hindi et al. introduced the concept of Blockchain DB with the aim of coming up with a shared database on blockchains [3]. Blockchain DB introduces a database layer on top of existing blockchain framework that extends the blockchains by classical data management techniques. The aim of blockchain DB is to increase performance and scalability of blockchains for data sharing but also decrease complexities for organizations intending to use blockchains as DB.
As El-Hindi et al. mentioned, there are two main reasons why blockchain’s are not being used widely:
- Limited scalability and performance:
Even the state of the art blockchain systems like Ethereum or Hyperledger can only achieve 10’s or max 100’s of transactions per second which is way below the requirements of modern applications.
- They lack easy to use abstractions:
Current blockchain systems lack a simple query interface and guarantees such as well-defined consistency levels that guarantee when and how updates become visible. Most of them come with proprietary programming interfaces.
Blockchain DB attempts to address these main issues for blockchain data management. It leverages blockchains as a storage layer. This way, existing blockchain systems can be used without modification as tamper proof and decentralized storage. On top of the storage layer, Blockchain DB adds a database layer which implements partitioning & replication and query interface & consistency.
Blockchain DB also offers off-chain verification procedures in which clients can detect potential misbehaving peers in the Blockchain DB network. It also offers attacks and trust guarantees against changing shared state to anyone’s advantage and detecting malicious peers. It comes in two flavors, offline verification and online verification. El-Hindi et al. mentions the advantages and disadvantages of each but specify that offline verification is preferred and is less costly. The following figure illustrates the structure of a Blockchain DB network as proposed in the paper by El-Hindi et al.
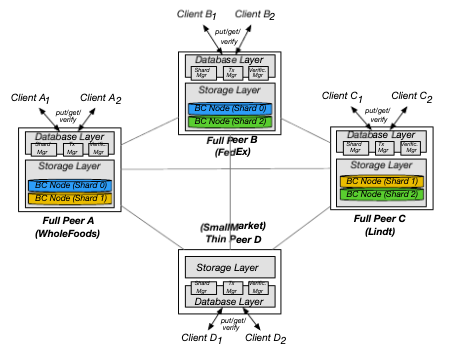
Fig 2. Typical Blockchain DB network
In the database layer, Blockchain DB additionally provides easy to use abstractions including different consistency protocols namely eventual consistency and sequential consistency which is described in detail in the paper.
- Eventual consistency:
For eventual consistency, a get-operation is immediately answered, however, no guarantee is given that a potential outstanding put operation has already been committed to the blockchain.
- Sequential consistency:
Here, the database layer needs to execute put/get operations in order and this potentially blocks a get-operation until an outstanding put-operation has been committed to the blockchain.
3. VISUALIZATION CHALLENGES IN BLOCKCHAIN
In section 3, we understood one popular blockchain data modelling technique using Blockchain DB. Having such a model in place will indeed make our data analytics and visualization tasks easier. Now, let’s back to the visualization and data analytics understanding which we gained in section 2. We understood how analytics taxonomy can help us set out analysis goals and most of the analytics results in a visualization which helps convey the information effectively. Although, there are some significant challenges identified by Tovanich et al. in their paper. Let’s discuss each of them:
- Multiple views of visualization of blockchain data:
- Currently, most of the visualizations are single view charts showing particular blockchain measure overtime.
- These single disconnected views make it difficult to release multiple blockchain characteristics to each other.
- New visual representations for transaction network and analysis:
- Existing visualizations present transaction networks and value flows as static graphs at specific points of interests and there is a need to have dynamic network visualizations.
- Uncertainty visualization:
- Sometimes, analysis tools may label certain transaction patterns as fraudulent and may make false predictions.
- Any uncertainty in the data should be made evident in the visualization.
- Progressive visual analytics:
- The blockchain evolves over time, for example, continuous evolution for maintaining clustered Bitcoin entities up to date.
- There is a need to have computationally efficient visualizations and progressive visual analytics for processing large amounts of data from ever evolving blockchain.
4. DATA ANALYSIS CHALLENGES FOR BLOCKCHAIN
Almost every blockchain system uses a key-value store as the underlying data storage mechanism. Key-value stores offer a great amount of flexibility and cost & space efficient storage. Although, as we know, key-value stores are optimized only for data with a single key and value, when there are multiple nested key-value pairs, a parser is required. This also makes it inefficient for lookup operations, as lookup requires scanning the entire collection or creating separate index values. Since key-value stores are mostly unstructured, it becomes difficult to put foreign keys which might be needed for looking up values in a lookup or other tables. Although, we still can create an intermediate table that would act as a key-value store for holding foreign key references, it is still a costly and less efficient affair. For data analysis, we often crunch a lot of data and view it from different perspectives and perform a lot of joins or aggregations on the data and it may become painful if the underlying data store doesn’t offer much support for this. Also, maintaining integrity and consistency among data attributes is a key thing to monitor, since there are no database constraints, it is easily possible to create new attribute names for the same value which might affect the maintainability, but due to the current programming practices, such mistakes may not occur frequently.
5. DATA ANALYTICS FOR BENCHMARKING BLOCKCHAIN SYSTEM
The purpose of this section is to describe a key application of blockchain oriented data analytics which is Benchmarking. One of the prominent applications of any data analytics work is benchmarking. Dinh et al. proposes the BlockBench framework for analyzing private blockchains. They present the first benchmarking framework for understanding and comparing performance of permissioned blockchain systems. In their research, they conduct comprehensive evaluations of Ethereum, Parity and Hyperledger which present concrete evidence of blockchain’s limitations in handling data processing workloads and reveal bottlenecks and these systems serve as a baseline for further development of blockchain technologies.
The aim of BlockBench is to provide better understanding of the performance and design of different private blockchain systems. Their research attempts to find the limitations in Bitcoin, Ethereum and Hyperledger systems. Interestingly, it is possible to link the understanding gained from section 2, 3 and 4 to BlockBench. It takes into consideration the importance of data modelling for any blockchain framework to perform optimally and also demonstrates their finding in several different information visualizations based on several different task domains. Although, their main objective of data analytics on blockchain systems is to perform evaluation and bring up possible limitations and bottlenecks in a blockchain framework with respect to performance and data processing workloads. Since we are focusing more on data science, let’s understand the key limitations of each of the three blockchain frameworks analyzed by BlockBench. Below are the key bottlenecks they report with respect to each of the three blockchain frameworks they analyzed:
- Hyperledger:
- Blockbench identifies that there is a trade off in data models.
- The key-value model of hyperledger means analytical queries cannot be supported, although it enables optimization which helps answering queries more efficiently.
- Parity:
- They identify that parity trades performance for scalability by keeping states in the memory.
- They state that bottleneck in parity is not due to the consensus protocol, but due to server’s transaction signing.
- Ethereum:
- They found that Ethereum was more mature of the 3 systems benchmarked, yet not ready for mass usage according to their finding.
- Ethereum incurs large overhead in terms of memory and disk usage for data processing.
6. FINAL WORDS
This blog focussed more on blockchain oriented data analytics from the perspective of visualization, data modelling and one of the applications of blockchain oriented data science which is benchmarking.
REFERENCES
- Tovanich et al. (2019). “Visualization of Blockchain Data: A Systematic Review.” IEEE Transactions on Visualization and Computer Graphics. http://ezproxy.library.uvic.ca/login?url=https://ieeexplore.ieee.org/abstract/document/8945380 (Survey paper on techniques for visualising blockchain data)
- Dinh et al. (2017) “BLOCKBENCH: A Framework for Analyzing Private Blockchains.” Proc. SIGMOD. http://ezproxy.library.uvic.ca/login?url=https://dl.acm.org/doi/10.1145/3035918.3064033 (Benchmarks multiple private and public blockchains against each other in terms of, e.g., data processing throughput)
- El-Hindi et al. (2019). “BlockchainDB – Towards a Shared Database on Blockchains.” SIGMOD. http://ezproxy.library.uvic.ca/login?url=https://dl.acm.org/doi/10.1145/3299869.3320237 (Database system paper with separate database and blockchain layers to support a key-value store architecture)
