

Differential Privacy
1. INTRODUCTION
The differential privacy is a data privacy protection mechanism which comes by adding randomness or noise to the data before it is published or made available for analysis. Which means, the more the noise the better the privacy. It is important to note the trade off between privacy of the data and the utility of the data itself. The threshold can be set according to the business context or specific requirements which is controlled using a privacy tuning parameter called Epsilon. The lower the epsilon, higher the noise which means highest privacy but it also means less utility of the data. The lowest epsilon value provides the highest level of privacy but at the cost of the utility and the highest epsilon value provides the lowest privacy but high data utility which essentially might not be sufficiently differentially private.
Let’s assume we identify an optimal epsilon value based on our requirements of privacy protection and make the data available for analysis through a query system. Since differentially private data means adding randomness/noise, each query issued to the data generates different output of records which contains noise in it. Although, after issuing a certain amount of queries, the issuer/attacker might be able to identify the patterns of the output which may enable the issuer/attacker to recognize or correctly guess the original value of record(s). So how is this handled? Let’s understand it later with an example in section 3.
2. UNDERSTANDING THE MECHANISM OF DIFFERENTIAL PRIVACY -BEGINNER’S PERSPECTIVE
| Name | Answer |
| Alice | Yes |
| Bob | No |
| Eliza | Yes |
| Frank | Yes |
| George | No |
| Mary | Yes |
| John | Yes |
(Table is inspired from: https://accuracyandprivacy.substack.com/)
Let’s assume we have the above table and the sensitive column being ‘Answer’ that we need to make differentially private, which means, adding noise to ‘Answer’. The amount of noise depends upon the epsilon parameter as we learnt above and we also need some degree of randomness which can be statistically traceable. Let’s understand it with the help of the following example.
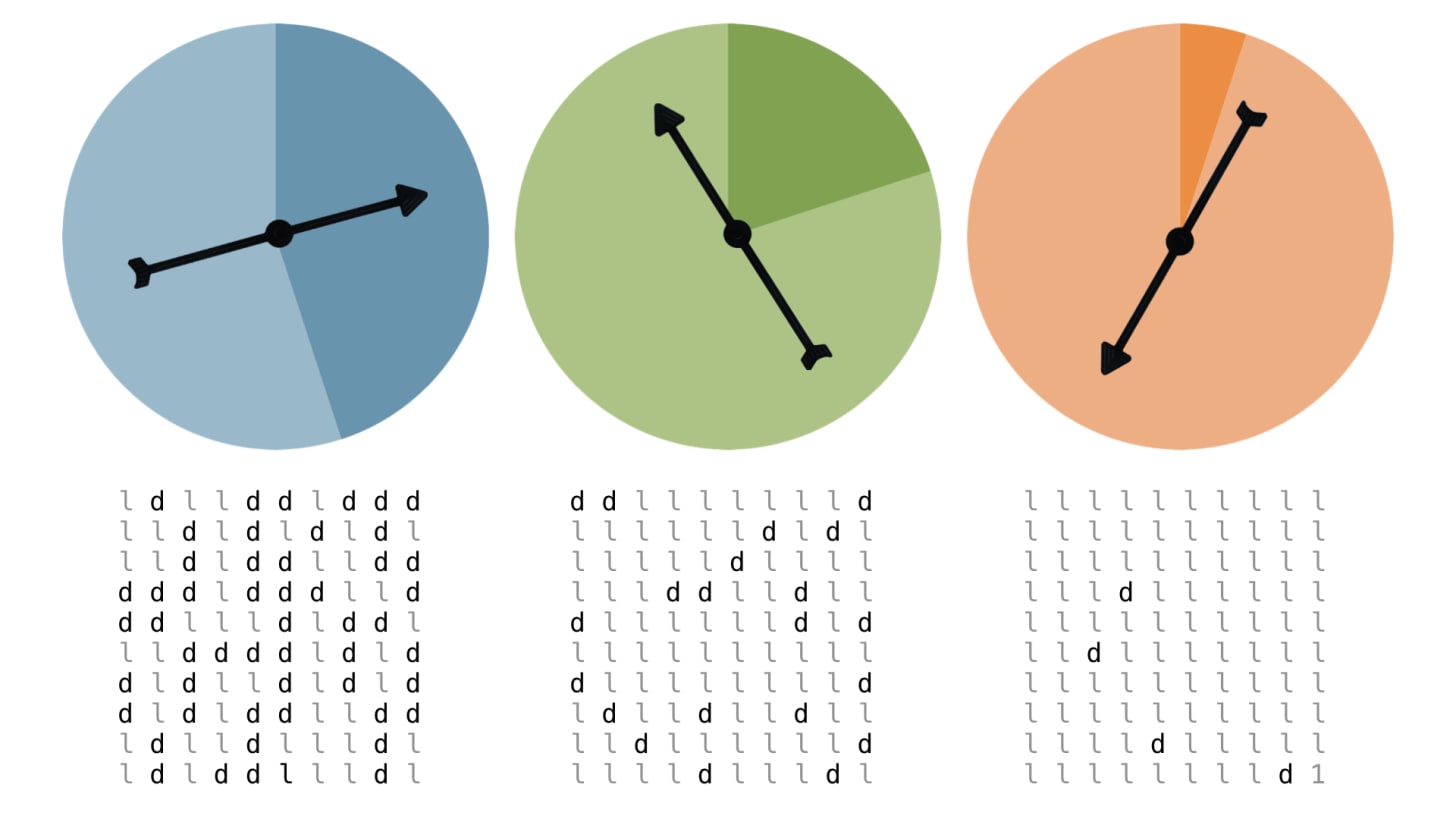
Fig 1. Spinners to represent the overview concept of differential privacy mechanism
The above figure illustrates three scenarios where each of them can be understood as having different epsilon values. The dial in the center is to have a degree of randomness. For the purpose of this example, let’s define a simple noise addition mechanism: if the tip of the dial stops in the light area we don’t change the ‘Answer’ and if it stops in dark area, we flip the ‘Answer’ i.e. if it’s yes then change it to no and vice versa. With this we have set up our noise addition mechanism. Also, we can correlate the light shade to our epsilon value the lower the value, the higher the noise and privacy of data and vice versa. Let’s say that our epsilon values are 0.55, 0.75 and 0.95 respectively for each of the above figures from left to right. After altering our results after each spin based on our noise addition mechanism, the randomized results are known to be differentially private. Let’s say we have 100 records in a dataset and consider we spin the dials to get the below results:
Fig 2. Output of each spinner after 100 spins
Looking at the above results, we can see that the first figure where epsilon was 0.55, many spins landed in the dark area, whereas when it was 0.75 relatively less spins landed in the dark area and when it was 0.95 just 4 spins landed in the dark area. This directly helps us to understand the underlying concept of differential privacy in simple terms. In real world setting, laplace or exponential mechanism is most popularly used for noise addition or randomness in epsilon differential privacy approach. But it is important to note that just adding noise or randomness doesn’t ensure that data will be entirely private. This is because, if the attacker continuously issues the same query, even if there is noise in the data, it is possible to infer the patterns of randomness or noise and achieve a closer guess or exactly recognize the original information of the target. In order to tackle this, the concept of privacy budget was introduced.
3. PRIVACY BUDGET
To control the number of queries issued to the dataset in order to prevent inference from randomized results, the concept of privacy budget comes in place. The lower the epsilon the higher the privacy budget and vice versa as we learnt in section 2. If we think of privacy budget in terms of money, then let’s assume we have a budget of 1 CAD [4]. This budget can be exhausted by issuing a single query that costs 1 CAD (provides all/enough information to the issuer by preserving privacy, if any further query is issued the privacy can be compromised) or one query that costs 0.60 CAD and 4 queries costing 0.10 CAD can be issued. With this we ensure that all the queries issued to the data comply within the privacy budget for each individual giving less opportunity to the issuer/attacker to infer the original data from the randomness of the data. Although, there is one challenge with this approach. If the query issuer issues ten 0.10 CAD queries, it is still possible to get different results for each of those 10 queries which could be sufficient enough to infer the originality from the randomness whereas everything is within the privacy budget. This problem can probably be addressed by caching the queries for each individual so that if the same query is issued, the same result is generated and also the privacy budget is not exhausted for the repetitive queries.
4. SENSITIVITY OF DATASET
In order to decide the privacy budget, it is good to know the sensitivity of the dataset to be made differentially private. In order to know the sensitivity, we apply a query function on two neighbouring subset of a dataset. We can make an assumption that these datasets differ from each other by one record. The sensitivity function gives us the maximum difference between the query results on the neighbouring datasets. This value helps determine the sensitivity of the dataset and make appropriate decisions in choosing a privacy budget.
delta(f) = max || f(d) − f(d′)||
5. DIFFERENTIAL PRIVACY MECHANISMS
There exist several theoretical differential privacy mechanisms, but below are the most widely used to guarantee differential privacy:
1. Laplace Mechanism
The Laplace mechanism adds independent noise to the original answer.
2. Exponential Mechanism
Mostly optimized for non-numeric queries to randomize the results which is paired with score function which evaluates the quality of the output.
6. UTILITY MEASUREMENT
Having differentially private data helps ensure privacy but it is also necessary to understand the usefulness of the data. This step is generally performed after the data is made differentially private. There are two widely used mechanisms:
1. Noise size measurement:
- This method helps us to know how much noise is added to the query results.
- This is the most commonly used method to measure the utility.
- The smaller the noise the higher the utility.
2. Error measurement:
- In this method we calculate the difference between non-private and private output.
- The lesser the difference, the higher the utility.
- It is generally represented by a bound with accuracy parameters. Until this point, we now have understood the key components and operating mechanisms of differential privacy. From the next section, we are going to see two important applications where differential privacy is highly applicable.
7. DIFFERENTIAL PRIVACY IN PRACTICE
7.1 Differentially private data publishing
At this stage, we can assume that we have all the optimal mechanisms to ensure that our dataset is ready to offer differential privacy. Now, this data needs to be published. In the real world setting, there are two identified settings involved:
1. Interactive setting:
- In this setting, the data curator applies each query to the dataset interactively.
- The next query cannot be issued to the curator until the answer to the previous query has been published.
2. Non-interactive setting
- In this setting, all the queries are given to the curator at one time and the curator can provide answers with full knowledge of the query set.
Now that we know some basics about these two settings, let’s understand them better with an example. Let’s consider we have the following dataset with some medical information [1].
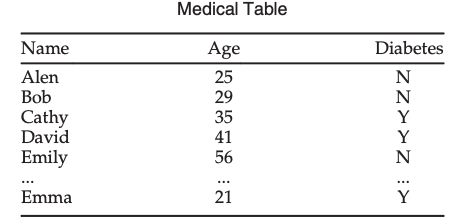
Table 2.: Example medical records dataset
Also, we have following queries for the data curator:
- How many patients have diabetes at the age of 40-79?
- How many patients have diabetes at the age of 40-59?
Let’s understand how the utility and privacy of the data is affected in both the settings.
A. Interactive setting:
- The curator receives the first query in the beginning.
- It sends the number of patients by query’s criteria.
- Then the curator adds independent laplace noise with sensitivity as 1, Lap(1/epsilon)
- Now, the next query comes in.
- It will be answered with a sensitivity of 2 as changing one person in the table may change the results of both the queries.
- Finally, the total noise added to the query set is Lap(1/epsilon) + Lap(2/epsilon).
B. Non-interactive setting:
- Both queries are submitted to the curator at the same time.
- The sensitivity measured is 2 since changing one person in the table may change the results of both the queries.
- Therefore, the total noise that will be added is 2*Lap(2/epsilon).
- This noise is greater than the interactive setting, this is because, correlation between queries leads to higher sensitivity. So what do we learn from it? We learn that non-interactive settings normally incur more noise than interactive settings. Although, both the examples indicate that the amount of noise increases dramatically when queries are correlated to each other. The reason behind this is the Laplace mechanism which makes it impractical in the scenarios that require answering large amounts of queries. There are several other mechanisms available which can be used depending on the requirement of number of queries, the accuracy of the output, and the computational efficiency. They are:
- Transformation
- Dataset partitioning
- Iteration
- Query Separation
Based on these, there are several techniques for interactive and non-interactive data publishing which are:
1. Interactive:
- Transaction data publishing
- Histogram publishing
- Stream data publishing
- Graph data publishing
2. Non-interactive:
- Batch query publishing
- Synthetic data publishing
7.2 DIFFERENTIALLY PRIVATE DATA ANALYSIS
Now, we touched upon the understanding of differentially private data publishing. Modern data science raises a concern on the different statistical analysis algorithms that are being used which knowingly or unknowingly make use of personally identifiable information in order to make predictive inferences. The key goal of differentially private data analysis is extending non-private algorithms to differentially private algorithms.
The differentially private data analysis can be realized by several frameworks categorized into two types:
- Laplace/exponential frameworks
- Private learning frameworks
A. Laplace/exponential frameworks
- Mostly all types of analysis algorithms can be implemented using this framework.
- Example can be adding noise to the count steps or perform exponential mechanisms when making selections.
- In practice, it can be applied to supervised learning, unsupervised learning or frequent itemset mining problems.
- Although, there are certain challenges associated with the use of this framework on supervised, unsupervised and frequent itemset mining types of learning.
- With supervised learning, the privacy budget has to be consumed multiple times due to the ensemble process involved in most of these algorithms and also there is a high possibility of inducing large amounts of noise.
- In case of unsupervised learning, high sensitivity of clustering centers can cause issues.
- For frequent itemset mining, the most common problem is large candidate itemsets, inducing noise or randomizing the patterns may lead to miss out on some of the important patterns within the dataset. Although, there are some modern implementation of differentially private platforms that make use of this framework one of them being Microsoft’s PINQ (Privacy Integrated Querying) platform which can automatically implement clustering algorithms and return differentially private results.
B. Private learning frameworks:
- This framework can only deal with limited learning problems.
- It considers data analysis as a learning problem in terms of optimization.
- Private learning frameworks combine differential privacy with diverse learning algorithms to preserve the privacy of the learning samples.
- The foundation of this framework is on the ERM and PAC learning theories.
- ERM helps to select the optimal learning model by transferring the learning process into a convex minimization problem. Differential privacy either adds noise to the output models or to the convex objective functions. PAC learning estimates the relationship between the number of learning samples and the models accuracy.
However, there are some limitations to the private learning frameworks. The ERM learning requires that the objective function should be convex and L-Lipschitz and PAC learning can only be applied when the algorithm is PAC learnable. These limitations prevent the practical development of these frameworks.
7.3 APPLICATIONS OF DIFFERENTIAL PRIVACY IN MODERN DATA SCIENCE
Tianqing Zhu et. al [1] highlights some key applications of differential privacy in the real world. The key applications are listed below:
- Location-Based Services
- Recommender Systems
- Genetic Data
REFERENCES
- Zhu et al. (2017). “Differentially Private Data Publishing and Analysis: A Survey.” IEEE Trans Data Knowl Eng. http://ezproxy.library.uvic.ca/login?url=https://ieeexplore.ieee.org/abstract/docum ent/7911185 (Very recent survey of state of the art in differential privacy)
- Dwork. “Differential Privacy.” ICALP 2006. http://ezproxy.library.uvic.ca/login?url=https://link.springer.com/chapter/10.1007/ 11787006_1 (Original paper introducing the notion of differential privacy)
- McSherry (2009). “Privacy integrated queries: An extensible platform for privacy-preserving data analysis.” SIGMOD. http://ezproxy.library.uvic.ca/login?url=https://dl.acm.org/doi/10.1145/1559845.15 59850 (Microsoft paper integrating differential privacy into a database system; also available as a lighter read in Comm. ACM).
- https://www.johndcook.com/blog/2019/10/14/privacy-budget/ (Accessed on: 05 March 2020).
- https://accuracyandprivacy.substack.com/ (Accessed on: 05 March 2020).

